Introduction to Bayesian Decision Making Toolbox BDM
This is a brief introduction into elements used in the BDM. The toolbox was designed for two principle tasks:
- Design of Bayesian decisions-making startegies,
- Bayesian system identification for on-line and off-line scenarios.
In order to achieve these principal goals in full generality, we need to implement full range of probabilistic operations such as: marginalization, conditioning, Bayes rule, combination of probability densities. Furthermore, many supportive operations are also required, such as data handling and logging of results. Here, we explain the basic classes for each task and point to advanced topics on the issue.
Philosophy of the Toolbox
The primary obstacle for creation of any any Bayesian software is how to address inherent computational intractability of the calculus. Typically, toolboxes implementing Bayesian calculus choose one particular task or one particular approximation methodology. For example, "BUGS" is a toolbox focused on evaluation using Gibbs sampling, "BNT" is focused on Bayesian Networks, "NFT" on Bayesian filtering. BDM takes another approach: all tasks are defined via their functional form, detailed implementation is an internal matter of each class.This philosophy results in a tree structure of inheritance, where the root is an abstract class. Different approaches to Bayesian calculus are implemented as specialization of this class. Interoperability of these classes is achieved by data classes, representing mathematical objects arising in the Bayesian calculus.
The task of Bayesian estimation decribed in the next Section is a good illustration of the philosophy.
Bayesian parameter estimation
Bayesian parameter estimation is, in essence, straightforward application of the Bayes rule:
![\[ f(\theta|D) =\frac{f(D|\theta)f(\theta)}{f(D)}\]](form_81.png)
where, 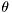 is an unknown parameter,
is an unknown parameter, 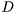 denotes the observed data,
denotes the observed data, 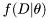 is the likelihood function,
is the likelihood function, 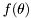 is the prior density, and
is the prior density, and 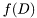 is "evidence" of the data.
is "evidence" of the data.
This simple rule has, however, many incarnations for various types of the likelihood, prior and evidence. For example, the Bayes rule can be evaluated exactly for likelihood function from the Exponential Family and conjugate prior, where the whole functional operation reduces to algebraic operation on sufficient statistics. For other likelihood functions and priors, various approximate schemes (such as Monte Carlo sampling, or maximum-likelihood optimizations) were proposed. To capture all of these options, we abstract the core functionality in the class BM:
-
or
void bayes(vec dt)void bayesB(mat D) -
epdf& _epdf().
Hence, the class represent an "estimator" that is capable of returning a posterior density (via method _epdf ) and application of the Bayes rule vis method bayes .
Functions bayes and bayesB denotes on-line and off-line scenario, respectively. Function bayes assumes that
- Parameters:
-
dt is an incremental data record and applies the Bayes rule using posterior density for the previous step as a prior. On the other hand, bayesBassumes thatD is the full data record, and uses the original prior created during construction of the object.
epdf . When we are interested only in part of the posterior density we can apply probability calculus via methods of this class.Probability calculus
Key objects of probability calculus are probability density functions, pdfs. We distinguish two types of pdfs: , with numerical statics
, with numerical statics  , and mpdf, a pdf conditioned on another random variable:
, and mpdf, a pdf conditioned on another random variable:  , where
, where  is a variable.
is a variable. The principal distinction between these types is that operations defined on these classes have different results. For example, the first moment of the former is a numeric value, while for the latter it is a functional form.
The most important operations on pdfs are:
double evallog(vec dt)
epdf and double evallogcond()
mpdf. marginalization: implemented by method for epdf, conditioning: implemented by method for epdf.
Note that a new data class, RV, is introduced. This class represents description of a multivariate random variable.
Random Variables
In mathematics, variable is a symbol of quantity that has no assigned value. Its purpose is to distinguish one variable from another. Hence, in software representation it has a meaning of unique identifier. Since we allow multivariate random variables, the variable also carries its dimensionality. Moreover, for dealing with time-varying estimation it also makes sense to distinguish different time-shift of variables.The main purpose of this class is to mediate composition and decomposition of pdfs. See,...
