Howto Use BDM - System, Data, Simulation
This section serves as introdustion to the scenario of data simulation. Since it is the simpliest of all scenarios defined in BDM Use - Introduction it also serves as introduction to configuration of an experiment (see ui) and basic decision making objects (bdm::RV and bdm::DS).
All experiments are demonstarted on scenario simulator which can be either standalone application of mex file (simulator.mex**).
Configuration of an experiment
Configuration file (or config structure) is organized as a tree of information. High levels represent complex structures, leafs of the tree are basic data elements such as strings, numbers or vectors.
Specific treatment was developed for objects. Since BDM is designed as object oriented library, the configuration was designed to honor the rule of inheritance. That is, offspring of a class can be used in place of its predecessor. Hence, objects (instances of classes) are configured by a structure with compulsory field class. This is a string variable corresponding to the name of the class to be used.
The configuration has two possible options:
- configuration file using syntax of libconfig (see ui),
- matlab structure. For the purpose of tutorial, we will use the matlab notation. These two options can be mutually converted from one to another using prepared mex files: config2mxstruct.mex and mxstruct2config.mex. Naturally, these scripts require matlab to run. If it is not available, manual conversion is relatively trivial, the major difference is in using different types of brackets (ui)
First experiment
The first experiment that can be performed is:
DS.class='MemDS';
DS.Data =[1 2 3 4 5 6];
which can be found in file bdmtoolbox/tutorials/userguide/memds_example.m.
The code above is the minimum necessary information to run scenario simulator in matlab. To actually do so, make sure that matlab can find the simulator.mex file, e.g. by running:
>> addpath _path_to_/bmtoolbox/mex/
The expected result for Matlab is:
>> M=simulator(DS)
M =
ch0: [6x1 double]
If you see this result, you have configured BDM correctly and you have sucessfully run you first experiment. In other cases, please check your installation, installation. All that the simulator did was actually copying DS.Data to M.ch0. Explanation of the experiment and the logic used there follows.
Systems and DataSources
In standard system theory, the system is typically illustrated graphically as:

Where u typically denotes input and y denotes output of the system. A causal dependence between input and output is typically presumed.
We are predominantly concerned with discrete-time systems, hence, we will add indeces  to both input and output,
to both input and output, 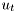 and
and 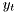 . We presume that the causal dependence is comes before .
. We presume that the causal dependence is comes before .
One of the definition of a system is that system is a "set of variables observed on a part of the world". Under this definition system is understood as generator of data. This definition may be a considered too simplistic, but it serves well as a description of what software object DataSource is.
DataSource is an object that is essentially:
- able to return data observed at time
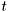 , (bdm::DS::getdata()),
, (bdm::DS::getdata()), - able to perform one a time step, (bdm::DS::step()).
- able to describe what these data are, (bdm::DS::_drv()),
No fruther specification, e.g. if the data are pre-recorded or computed on-the-fly, are given. Specific behaviour of various DataSources is implemented as specialization of the root class bdm::DS.
DataSource of pre-recorded data -- MemDS
The first experiment run in First experiment was actually an instance of DataSource of pre-recorded data that were stored in memory, i.e. the bdm::MemDS class.
Operation of such object is trivial, the data are stored as a matrix and the general operations defined above are specialized as follows:
- data observed at time are columns of the matrix, getdata() ruturns current column,
- time step itself is performed by increasing the column index,
- each row is named as "ch0","ch1",...
This is the default bahavior. It can be customized using the UI mechanism. When the object of class MemDS is created it calls method bdm::MemDS::from_setting() and the input structure is parsed for settings. All available settings are documented in the method, see bdm::MemDS::from_setting(). The options are:
DS.class = 'MemDS'; DS.Data = (...); // Data matrix or data vector --- optional --- DS.drv = RV({"ch0",...} ); // Identification how rows of the matrix Data will be known to others DS.time = 0; // Index of the first column to user_info, DS.rowid = [1,2,3...]; // ids of rows to be used
The compulsory fields are listed at the beginning; the optional fields are separated by string "--- optional ---".
Fields time and rowid are self-explanatory. Field drv is a the one that specifies identification of the data elements, (point 3. of the general requirements of a DataSource).
All optionals fields will be filled by default values, it this case:
DS.drv = RV({'ch0'},1,0);
DS.time = 0;
DS.rowid = [1];
Where the first line specifies a universal identification structure: random variable (bdm::RV).
What is RV and how to use it
RV stands for random variable which is a description of random variable or its realization. This object playes role of identifier of elements of vectors of data (in datasources), expected inputs to functions (in pdfs), or required results (operations conditioning).
Mathematical interpretation of RV is straightforward. Consider pdf 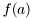 , then
, then 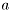 is the part represented by RV. Explicit naming of random variables may seem unnecessary for many operations with pdf, e.g. for generation of a uniform sample from <0,1> it is not necessary to specify any random variable. For this reason, RV are often optional information to specify. However, the considered scenanrio
is the part represented by RV. Explicit naming of random variables may seem unnecessary for many operations with pdf, e.g. for generation of a uniform sample from <0,1> it is not necessary to specify any random variable. For this reason, RV are often optional information to specify. However, the considered scenanrio simulator is build in a way that requires RV to be given.
The simulator scenario connects the DataSource to second basic class of BDM, bdm:logger. The logger is a class that take care of storing results -- in this case, results of simulation. The connection between these blocks is done automatically. The logger stores results of simulations under the names specified in drv. Readers familiar with Simulink environment may look at the RV as being unique identifiers of inputs and outputs of simulation blocks. The inputs are connected automatically with the outputs with matching RV. This view is however, very incomplete, RV have more roles than this.
Loggers for flexible handling of results
Loggers are universal objects for storing and manipulating the results of an experiment. Similar to DataSource, every logger has to provide basic functionality:
- initialize its storage (bdm::logger.init()),
- assign a connection point to each interested object (bdm::logger.logadd()),
- accept data to be logged to given connection (bdm::logger.logit()),
- finalize the storage when experiment is finished.
These abstarct operations can be specialized in many ways. For example, storing all results in memory and writing them to disc when finished (bdm::memlog), storing data in a matlab structure (bdm::mexlog), writing them out in ascii (bdm::stdlog) or more sophisticated buffered output to harddrive (bdm::dirfilelog).
Since all experiments are performed in matlab, the default mexlog class will be used. However, the way how the results are to be stored can be configured using configuration structure filled by fields from from_setting of the chosen logger, and passing it as third argument to simulator.
Class inheritance and DataSources
As mentioned above, the scenario simulator is written to accept any datasource (i.e. any offspring of bdm::DS). For full list of offsprings, click see Classes > Class Hierarchy.
At the time of writing this tutorial, available datasources are bdm::DS
The MemDS has already been introduced in the example in DataSource of pre-recorded data -- MemDS. However, any of the classes listed above can be used to replace it in the example. This will be demonstrated on the EpdfDS class.
Brief decription of the class states that EpdfDS "Simulate data from a static pdf (epdf)". The static pdf means unconditional pdf in the sense that the random variable is conditioned by numerical values only. In mathematical notation it could be both 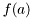 and
and  . The latter case is true only when all
. The latter case is true only when all  denotes observed values.
denotes observed values.
For example, we wish to simulate realizations of a Uniform pdf on interval <-1,1>. This is achieved by plugging an object representing uniform pdf into general simulator of independent random samples, EpdfDS. Uniform density is implemented as class bdm::euni. An instance of euni can be again created method from_setting, in this case bdm::euni.from_setting(). Using documentation we define it with the following code:
U.class='euni'; U.rv = RV({'a'}); U.high = 1.0; U.low = -1.0;
which encodes information:
![\[ f(a) = \mathcal{U}(-1,1) \]](form_160.png)
The datasource itself, i.e. the instanc of EpdfDS can be then configured via:
DS.class = 'EpdfDS';
DS.epdf = U;
where U is the structure defined above.
Contrary to the previous example, we need to tell to algorithm simulator how many samples from the data source we need. This is configured by variable experiment.ndat. The configuration has to be finalized by:
experiment.ndat = 10; M=simulator(DS,experiment);
The result is as expected in field M.a the name of which corresponds to name of U.rv .
If the task was only to generate random realizations, this would indeed be a very clumsy way of doing it. However, the power of the proposed approach will be revelead in more demanding examples, one of which follows next.
Simulating autoregressive model
Consider the following autoregressive model:
![\[ f(y_t|y_{t-3},u_{t-1}) = \mathcal{N}( a y_{t-3} + b u_{t-1}, r) \]](form_161.png)
where 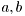 are known constants, and
are known constants, and  is known variance.
is known variance.
Direct application of EpdfDS is not possible, since the pdf above is conditioned on values of  and
and  . We need to handle two issues:
. We need to handle two issues:
- extra unsimulated variable
 ,
, - time delayes of the values.
The first issue can be handled in two ways. First, can be considered as input and as such it could be externally given to the datasource. This solution is used in scenario closedloop. However, for the simulator scenario we will apply the second option, that is we complement  by extra pdf:
by extra pdf:
![\[ f(u_t) = \mathcal{N}(0, r_u) \]](form_162.png)
where  is another known constant. Thus, the joint density is now:
is another known constant. Thus, the joint density is now:
![\[ f(y_{t},u_{t}|y_{t-3},u_{t-1}) = f(y_{t}|y_{t-3},u_{t-1})f(u_{t}) \]](form_155.png)
and we have no need for input since the datasource have all necessary information inside. All that is required is to store them and copy their values to appropriate places.
That is done in automatic way using dedicated class bdm::datalink_buffered. The only issue a user may need to take care about is the missing initial conditions for simulation. By default these are set to zeros. Using the default values, the full configuration of this system is:
y = RV({'y'});
u = RV({'u'});
fy.class = 'mlnorm<ldmat>';
fy.rv = y;
fy.rvc = RV({'y','u'}, [1 1], [-3, -1]);
fy.A = [0.5, -0.9];
fy.const = 0;
fy.R = 0.1;
fu.class = 'enorm<ldmat>';
fu.rv = u;
fu.mu = 0;
fu.R = 0.2;
DS.class = 'MpdfDS';
DS.mpdf.class = 'mprod';
DS.mpdf.mpdfs = {fy, epdf2mpdf(fu)};
Explanation of this example will require few remarks:
- class of the
fyobject is 'mlnorm<ldmat>' which is Normal pdf with mean value given by linear function, and covariance matrix stored in LD decomposition, see bdm::mlnorm for details. - naming convention 'mlnorm<ldmat>' relates to the concept of templates in C++. For those unfamiliar with this concept, it is basicaly a way how to share code for different flavours of the same object. Note that mlnorm exist in three versions: mlnorm<ldmat>, mlnorm<chmat>, mlnorm<fsqmat>. Those classes act identically the only difference is that the internal data are stored either in LD decomposition, choleski decomposition or full matrices, respectively.
- the same concept is used for enorm, where enorm<chmat> and enorm<fsqmat> are also possible. In this particular use, these objects are equivalent. In specific situation, e.g. Kalman filter implemented on Choleski decomposition (bdm::KalmanCh), only enorm<chmat> is approprate.
- class 'mprod' represents the chain rule of probability. Attribute
mpdfsof its configuration structure is a list of conditional densities. Conditional density is represented by class
is represented by class mpdfand its offsprings. ClassRVis used to describe both variables before conditioning (fieldrv) and after conditioning sign (fieldrvc). - due to simplicity of implementation, mprod accept only conditional densities in the field
mpdfs. Hence, the pdf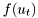 must be converted to conditional density with empty conditioning,
must be converted to conditional density with empty conditioning, 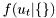 . This is achieved by calling function epdf2mpdf which is only a trivial wrapper creating class bdm::mepdf.
. This is achieved by calling function epdf2mpdf which is only a trivial wrapper creating class bdm::mepdf.
The code above can be immediatelly run, usin the same execution sequence of estimator as above.
Initializing simulation
When zeros are not appropriate initial conditions, the correct conditions can be set using additional commands (see bdm::MpdfDS.from_setting() ):
DS.init_rv = RV({'y','y','y'}, [1,1,1], [-1,-2,-3]);
DS.init_values = [0.1, 0.2, 0.3];
The values of init_values will be copied to places in history identified by corresponding values of init_rv. Initial data is not checked for completeness, i.e. values of random variables missing from init_rv (in this case all occurences of ) are still initialized to 0.
BDM is a library of basic components for Bayesian decision making, hence its direct use is not possible. In order to use BDM the components must be pulled together in order to achieve desired functionality. We expect two kinds of users:
- Basic users who run prepared scripts with different parameterizations and analyze their results,
- Advanced users who are able to understand the logic of BDM and extend its functionality to new applications.
The primary design aim of BDM was to ease development of complex algorithms, hence the target user is the advanced one. However, running experiments is the first task to learn for both types of users.
Experiment is fully parameterized before execution
Experiments in BDM can be performed using either standalone applications or function bindings in high-level environment. A typical example of the latter being mex file in Matlab environment.
The main logic behind the experiment is that all necessary information about it are gathered in advance in a configuration file (for standalone applications) or in configuration structure (Matlab). This approach was designed especially for time consuming experiments and Monte-Carlo studies for which it suits the most.
For smaller decision making tasks, interactive use of the experiment can be achieved by showing the full configuration structure (or its selected parts), running the experiment on demand and showing the results.
Semi-interactive experiments can be designed by sequential run of different algorithms. This topic will be covered in advanced documentation.
Configuration of an experiment
Configuration file (or config structure) is organized as a tree of information. High levels represent bigger structures, leafs of the structures are basic data elements such as strings, numbers or vectors.
Specific treatment was developed for objects. Since BDM is designed as object oriented library, the configuration was designed to honor the rule of inheritance. That is, offspring of a class can be used in place of its predecessor. Hence, objects (instances of classes) are configured by a structure with compulsory field class. This is a string variable corresponding to the name of the class to be used.
Consider the following example:
DS = {class="MemDS";
data = [1, 2, 3, 4, 5, 6, 7];
}
or written equivalently in Matlab as
DS.class='MemDS';
DS.Data =[1 2 3 4 5 6];
The code above is the minimum necessary information to run a pre-made algorithm implemented as executable estimator or Matlab mex file estimator. The expected result for Matlab is:
>> M=estimator(DS,{})
M =
ch0: [6x1 double]
The structure M has one field called ch0 to which the data from DS.Data were copied. This was configured to be the default behavior which can be easily changed by adding more information to the configuration structure.
First, we will have a look at all options of MemDS.
DataSource of pre-recorded data -- MemDS
As a first step, the estimator algorithm has created an object of class MemDS and called its method bdm::MemDS::from_setting(). This is a universal method called when creating an instance of class from configuration. Object that does not implement this method can not be created automatically from configuration.
The documentation contains the full structure which can be loaded. e.g.:
{ class = 'MemDS';
Data = (...); // Data matrix or data vector
--- optional ---
drv = {class='RV'; ...} // Identification how rows of the matrix Data will be known to others
time = 0; // Index of the first column to user_info,
rowid = [1,2,3...]; // ids of rows to be used
}
for MemDS. The compulsory fields are listed at the beginning; the optional fields are separated by string "--- optional ---".
For the example given above, the missing fields were filled as follows:
drv = {class="RV"; names="{ch0 }"; sizes=[1];};
time = 0;
rowid = [1];
Meaning that the data will be read from the first column (time=0), all rows of data are to be read (rowid=[1]), and this row will be called "ch0".
- Note:
- Mixtools reference This object replaces global variables DATA and TIME. In BDM, data can be read and written to a range of
datasources, objects derived from bdm::DS.
What is RV and how to use it
RV stands for random variable which is a description of random variable or its realization. This object playes role of identifier of elements of vectors of data (in datasources), expected inputs to functions (in pdfs), or required results (operations conditioning).
- Note:
- Mixtools reference RV is generalization of "structures"
strin Mixtools. It replaces channel numbers by string names, and adds extra field size for each record.
Mathematical interpretation of RV is straightforward. Consider pdf , then is the part represented by RV. Explicit naming of random variables may seem unnecessary for many operations with pdf, e.g. for generation of a uniform sample from <0,1> it is not necessary to specify any random variable. For this reason, RV are often optional information to specify. However, the considered algorithm estimator is build in a way that requires RV to be given.
The estimator use-case expects to join the data source with an array of estimators, each of which declaring its input vector of data. The connection will be made automatically using the mechanism of datalinks (bdm::datalink). Readers familiar with Simulink environment may look at the RV as being unique identifiers of inputs and outputs of simulation blocks. The inputs are connected automatically with the outputs with matching RV. This view is however, very incomplete, RV are much more powerful than this.
Class inheritance and DataSources
As mentioned above, the algorithm estimator is written to accept any datasource (i.e. any offspring of bdm::DS). For full list of offsprings, click Classes > Class Hierarchy.
At the time of writing this tutorial, available datasources are bdm::DS
The MemDS has already been introduced in the example in DataSource of pre-recorded data -- MemDS. However, any of the classes listed above can be used to replace it in the example. This will be demonstrated on the EpdfDS class.
Brief decription of the class states that EpdfDS "Simulate data from a static pdf (epdf)". The static pdf means unconditional pdf in the sense that the random variable is conditioned by numerical values only. In mathematical notation it could be both and . The latter case is true only when all denotes observed values.
For example, we wish to simulate realizations of a Uniform density on interval <-1,1>. Uniform density is represented by class bdm::euni. From bdm::euni.from_setting() we can find that the code is:
U={class="euni"; high=1.0; low = -1.0;}
for configuration file, and
U.class='euni'; U.high = 1.0; U.low = -1.0; U.rv.class = 'RV'; U.rv.names = {'a'};
for Matlab.
The datasource itself, can be then configured via
DS = {class='EpdfDS'; epdf=@U;};
in config file, or
DS.class = 'EpdfDS';
DS.epdf = U;
in Matlab.
Contrary to the previous example, we need to tell to algorithm estimator how many samples from the data source we need. This is configured by variable experiment.ndat. The configuration has to be finalized by:
experiment.ndat = 10;
M=estimator(DS,{},experiment);
The result is as expected in field M.a the name of which corresponds to name of U.rv .
If the task was only to generate random realizations, this would indeed be a very clumsy way of doing it. However, the power of the proposed approach will be revelead in more demanding examples, one of which follows next.
Simulating autoregressive model
Consider the following autoregressive model:
![\[ y_t \sim \mathcal{N}( a y_{t-3} + b u_{t-1}, r) \]](form_147.png)
where are known constants, and is known variance.
Direct application of EpdfDS is not possible, since the pdf above is conditioned on values of and . We need to handle two issues:
- extra unsimulated variable ,
- time delayes of the values.
The first issue can be handled in two ways. First, can be considered as input and as such it could be externally given to the datasource. This solution is used in algorithm use-case closedloop. However, for the estimator scenario we will apply the second option, that is we complement by extra pdf:
![\[ u_t \sim \mathcal{N}(0, r_u) \]](form_154.png)
Thus, the joint density is now:
and we have no need for input since the datasource have all necessary information inside. All that is required is to store them and copy their values to appropriate places.
That is done in automatic way using dedicated class bdm::datalink_buffered. The only issue a user may need to take care about is the missing initial conditions for simulation. By default these are set to zeros. Using the default values, the full configuration of this system is:
y = RV({'y'});
u = RV({'u'});
fy.class = 'mlnorm<ldmat>';
fy.rv = y;
fy.rvc = RV({'y','u'}, [1 1], [-3, -1]);
fy.A = [0.5, -0.9];
fy.const = 0;
fy.R = 0.1;
fu.class = 'enorm<ldmat>';
fu.rv = u;
fu.mu = 0;
fu.R = 0.2;
DS.class = 'MpdfDS';
DS.mpdf.class = 'mprod';
DS.mpdf.mpdfs = {fy, epdf2mpdf(fu)};
Explanation of this example will require few remarks:
- class of the
fyobject is 'mlnorm<ldmat>' which is Normal pdf with mean value given by linear function, and covariance matrix stored in LD decomposition, see bdm::mlnorm for details. - naming convention 'mlnorm<ldmat>' relates to the concept of templates in C++. For those unfamiliar with this concept, it is basicaly a way how to share code for different flavours of the same object. Note that mlnorm exist in three versions: mlnorm<ldmat>, mlnorm<chmat>, mlnorm<fsqmat>. Those classes act identically the only difference is that the internal data are stored either in LD decomposition, choleski decomposition or full matrices, respectively.
- the same concept is used for enorm, where enorm<chmat> and enorm<fsqmat> are also possible. In this particular use, these objects are equivalent. In specific situation, e.g. Kalman filter implemented on Choleski decomposition (bdm::KalmanCh), only enorm<chmat> is approprate.
- class 'mprod' represents the chain rule of probability. Attribute
mpdfsof its configuration structure is a list of conditional densities. Conditional density is represented by class mpdfand its offsprings. ClassRVis used to describe both variables before conditioning (fieldrv) and after conditioning sign (fieldrvc). - due to simplicity of implementation, mprod accept only conditional densities in the field
mpdfs. Hence, the pdf must be converted to conditional density with empty conditioning, . This is achieved by calling function epdf2mpdf which is only a trivial wrapper creating class bdm::mepdf.
The code above can be immediatelly run, usin the same execution sequence of estimator as above.
Initializing simulation
When zeros are not appropriate initial conditions, the correct conditions can be set using additional commands:
DS.init_rv = RV({'y','y','y'}, [1,1,1], [-1,-2,-3]);
DS.init_values = [0.1, 0.2, 0.3];
The values of init_values will be copied to places in history identified by corresponding values of init_rv. Initial data is not checked for completeness, i.e. values of random variables missing from init_rv (in this case all occurences of ) are still initialized to 0.
What was demonstrated in this tutorial
The purpose of this page was to introduce software image of basic elements of decision making as implemented in BDM.
- random values as identification mechanism (bdm::RV)
- unconditional pdfs (bdm::epdf),
- conditional pdfs (bdm::mpdf),
And the use of these in simulation of data and function of datasources. In the next tutorial, Bayesian models (bdm::BM) and loggers (bdm::logger) will be introduced.
